이전 GPT-1 논문을 안 읽어보신 분은 아래 포스팅을 참고해주세요!
[Paper Review] Improving Language Understanding by Generative Pre-Training
Question answering, machine translation, reading comprehension, 그리고 summarization과 같은 NLP task들은 주로 supervised 학습을 통한 접근법이 이뤄졌다. 본 논문은 모델을 WebText라는 데이터에 학습시켜 supervised 학습을 하지 않고 task에 적용시키는 연구를 진행했다. 학습된 모델은 CoQA 데이터셋에 대해 55 F1 성능을 달성했으며 4개 중 3개의 baseline 모델에 비해 더 나은 성능을 보이거나 비슷한 성능을 보였다. 모델 capacity는 zero-shot task에 적용시키기 위해 필수적이며, 확장시켰을 때 성능이 log-linear하게 증가한다.
논문에서 제시된 가장 큰 모델인 GPT-2는 1.5B개의 파라미터 수를 가진 Transformer 모델이며, 8개 중 7개의 평가 데이터셋에 대해 SOTA를 달성하지만 여전히 WebText에 대해선 일반화 능력이 부족하다(모델의 성능 발전 가능성이 있다는 뜻을 내포하는 것 같다).
Introduction
머신러닝 시스템은 큰 데이터셋, 큰 사이즈의 모델을 활용한 supervised 학습을 통해 좋은 성능을 발휘할 수 있었다. 이렇게 학습된 모델은 data distribution 및 task specification에 예민하며 범용적이기 보다는 특정한 task에 좋은 성능을 보인다고 할 수 있다. 따라서 다양한 task에 적용시킬 수 있는 범용적인 모델을 구축하고자 연구가 진행되었다.
다양한 single task training은 모델이 범용성을 갖지 못하게 되는 요인이며, 견고한 시스템을 구현하기 위해서는 시스템이 다양한 범위의 task에 대한 처리가 가능해져야 한다. 이를 뒷받침하여 최근에는 이러한 연구를 위해 GLUE, decaNLP와 같은 벤치마크가 제시되었다.
현재(논문이 써진 시점) 자연어 task에 대해 가장 높은 성능을 보이는 시스템은 pre-training과 fine-tuning으로 학습된 모델이다. 이 방법은 최종 task에 적용하기 위해 여전히 supervised 학습이 요구된다. 본 연구는 pre-training과 transfer learning 두 작업을 연결하고 좀 더 일반적인 전이 학습에 대한 연구를 진행하며, 언어 모델이 zero-shot setting으로 최종 task에 적용될 수 있음을 보여준다.
Methods
GPT-2의 핵심 method는 언어 모델링(language modeling, LM)이다. LM은 입력 샘플 $(x_1, x_2, \cdots, x_n)$ 및 다양한 길이의 symbol $(s_1, s_2, \cdots, s_n)$로부터 unsupervised 분포 예측을 진행함으로서 학습한다. 언어는 한 방향으로 흐르는 자연스러운 순서로 이뤄졌기 때문에 다음과 같은 조건부 확률로 나타낼 수 있다:

이러한 LM의 접근 방식은 샘플링뿐만 아니라 $p(s_{n-k}, \cdots, s_n | s_1, \cdots, s_{n-k-1})$과 같이 예측 token 개수를 늘린 확률 분포도 예측할 수 있게 한다. 최근(연구가 진행된 시점)에는 self-attention 구조를 활용한 Transformer의 등장으로 이러한 조건부 확률을 계산하기 위한 모델들의 성능이 대폭 높아질 수 있었다.
기존의 single task를 위한 조건부 확률 분포는 $p(output | input)$와 같은 framework를 가지고 있다. GPT-2는 모델이 범용적인 task를 수행할 줄 알아야 한다고 주장하며 $p(output | input, task)$와 같은 framework를 제시한다. 이로써 모델은 동일한 입력에 대해서 다양한 task를 수행할 수 있게 된다. 지난 연구들은 task conditioning을 구조적으로 구현하려고 했지만, GPT-2는 언어의 이점을 활용하여 task를 명시한다. 예를 들어 입력을 (translate to french, english text, french text)를 입력하면 기계 번역 학습이 되고, (answer the question, document, question, answer)를 입력으로 주면 reading comprehension을 학습할 수 있게 된다. 언어의 순방향대로 학습하는 auto-regressive LM 방식을 사용했기 때문에 이러한 학습방식을 사용할 수 있게 된다.
Training Dataset
기존의 데이터가 제한적일 수 있다는 가정 하에, GPT-2는 인터넷의 방대한 자료를 활용하여 모델을 학습시키기로 결정한다. 이론적으로 인터넷의 다양하고 많은 양의 데이터를 모델이 학습한다면 다양한 task를 처리하는 것을 학습할 것이고 이를 통해 unsupervised multitask learning이 가능해진다.
GPT-2는 모델이 zero-shot 예측이 가능하도록 다양한 task에 대한 데이터를 얻기 위해 최대한 많은 양과 다양한 종류를 가진 데이터를 활용하여 학습시키는 것을 목표로 한다. 인터넷 크롤하는 방식을 통해 데이터를 수집하면 방대한 양에 비해 퀄리티가 떨어질 수도 있다. 지난 연구는 이러한 크롤링 방식의 데이터들은 대부분 이해하기가 어렵다고 설명했다.
이를 해결하기 위해 문서 퀄리티를 강조한 새로운 스크랩 방식을 제안한다. 사람이 걸러낸 웹을 크롤하는데, 모든 링크를 가져오려면 너무 많기 때문에 Reddit에서 3 이상의 karma(점수)를 가진 모든 외부 링크를 참고한다. Karma로 웹 링크가 흥미로운 내용인지를 판별할 수 있다.
최종적으로 수집된 데이터를 WebText라고 부르고, 45M개의 링크 수를 포함한다. HTML로부터 텍스트를 가져오기 위해서 Dragnet, Newspaper 추출기를 사용한다. WebText는 2017년 12월까지의 링크를 포함하고, 40GB에 해당하는 8M개의 문서가 정리되었다. Wikipedia 자료는 테스트 데이터와 겹칠 수 있어 제거되었다.
Input Representation
Language model이 범용적인 특성을 가지려면 모든 string에 대한 확률 분포를 계산할 수 있어야 한다. 현재 LM은 lower-casing, tokenization 등의 전처리 과정을 거쳐 모델링할 수 있는 string을 제한한다. 유니코드(UTF-8 byte)은 이 점을 충족시킬 수 있지만 여전히 byte-level은 word-level 모델링보다 성능이 떨어진다는 단점이 있다.
따라서 논문은 BPE를 채택한다. BPE(Byte Pair Encoding)는 character과 word 중간 지점이며 word-level 입력과 character-level 입력에 대해 서로 보간할 수 있다. BytePE라는 이름과 다르게 유니코드를 기반으로 구현된 BPE는 base vocab 130,000이 넘어가며, 이는 전형적인 BPE vocab 크기 32,000, 64,000과 확실히 차이난다. BPE를 byte-level에서 구현하면 base vocab size가 256 밖에 되지 않기 때문에 byte-level을 사용한다. 하지만 byte-level을 적용하는 것은 sub-optimal하기 때문에 BPE가 (dog. dog! dog?)와 같은 변형 토큰을 저장하는 것을 막기 위해 BPE가 character category 간의 합병을 하지 못하게 제한한다.
결론적으로 input representation은 word-level LM과 byte-level LM의 이점을 모두 사용할 수 있게 해주고, 모든 유니코드를 처리할 수 있기 때문에 어느 데이터셋에서도 평가가 가능하다.
Model
GPT-2는 Transformer 기반으로, GPT-1의 구조와 유사하다. 다른 점은, 정규화 레이어가 sub-block의 입력 부분으로 옮겨졌고, 마지막 self-attention block 바로 다음에 추가 정규화 레이어가 위치한다. 또한 residual 레이어의 깊이를 $N$이라고 했을 때, residual layer의 가중치를 $1 / \sqrt{N}$로 초기화한다. Vocabulary는 50,257로 확산되었으며, 배치 사이즈는 512로, context size는 512에서 1024 토큰으로 확장되었다.
Experiments
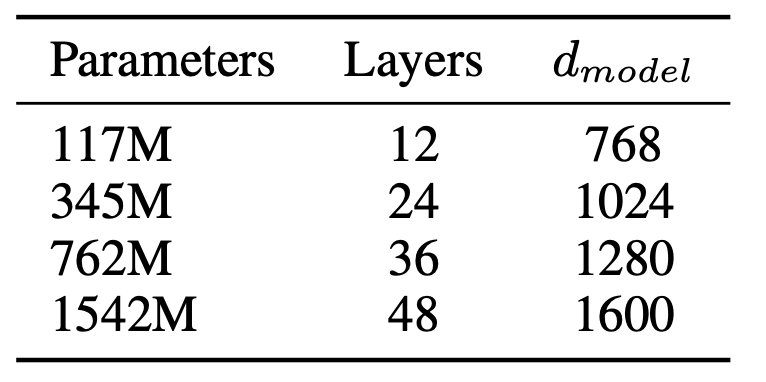
평가에 사용된 모델 사이즈는 [표 1]과 같다. 모델 크기는 대략적인 log-uniform 수치에 따라 정해졌다. 가장 작은 모델은 GPT-1과 비슷하고, 두번째 모델은 BERT의 가장 큰 모델과 크기가 비슷하다. 가장 크기가 큰 모델을 GPT-2라고 하며, 모델이 가진 파라미터는 GPT보다 월등히 많다. 모델의 학습률은 WebText에서 5%의 샘플을 사용하여 perplexity가 가장 낮아지는 수치로 선택했다.
학습된 GPT-2 모델의 zero-shot task 성능을 실험해보기 위해 다양한 task에서 성능을 평가한다. 모델은 out-of-distribution에 대해 평가되며, 기존 pre-processing을 사용한 모델은 de-tokenizer를 활용하여 원래의 텍스트에 학습되는 실험을 진행한다.

모델은 위와 같이 장기 의존성을 평가하는 LAMBDA, Children’s Book Test(CBT) 등의 다양한 데이터에 대해 평가되었다. GPT-2는 주로 작은 데이터에 대해 좋은 성능을 보였으며, [표 2]를 보면 One Billion Words 데이터셋을 제외하면 SOTA릉 달성한 지난 모델들보다 좋은 성능을 보인 것을 알 수 있다. 특히 LAMBDA는 기존에 비해 perplexity가 확연하게 낮아진 것을 확인할 수 있다.
GPT-2가 기계 번역을 수행하기 위해서는 (english text = french text) pair 몇개를 주며 마지막 줄은 (english text = ) 와 같이 입력하여 모델이 번역된 출력을 하도록 유도했다. WMT14 English-French 성능은 5 BLEU였고, WMT14 French-English는 그보다 높은 수치인 11.5 BLEU를 달성했다.
Discussions
GPT-2는 다음 토큰을 예측하는 LM과 방대한 데이터를 포함하는 WebText를 사용하여 zero-shot task 성능을 향상시킨 모델이다. 개인적으로 BERT는 기존의 AR 방식을 개선하기 위해 MLM을 제시했지만, 자연어의 순방향대로 학습하는 AR을 적극 활용하여 많은 데이터를 처리할 수 있도록 구현한게 굉장히 인상깊었다. 챗GPT에 사용된 GPT 3.5의 시초라고 할 수 있는 GPT-2 논문 리뷰를 마치도록 한다.
논문 참고하실 분들은 아래 링크로!
https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
