BERT(Bidirectional Encoder Representations from Transformers)는 2018년 Google에서 제시한 양방향 pre-trained 모델이다. 논문은 BERT에서 볼 수 있다. BERT는 양방향의 context를 모두 참조함으로써 모델이 deep bidirectional representation 학습이 가능하도록 한 것이 논문의 중요 포인트이다. 또한, pre-trained BERT는 fine-tuning을 통해 output layer를 하나만 추가함으로써 NLI 및 QA와 같은 downstream tasks에 손쉽게 적용할 수 있다.
Introduction
기존의 Pre-trained 모델은 많은 NLI, QA, paraphrasing와 같은 sentence 사이의 관계를 다루는 language tasks에서 좋은 성능을 보였다. 모델을 사전훈련 시키는 방식은 크게 두 가지가 있다: feature-based, fine-tuning. ELMo와 같은 feature-based 모델들은 pre-trained representations을 포함한 task-specific 구조를 사용한다. GPT와 같은 fine-tuning 방식은 소량의 파라미터를 추가해서 간단하게 downstream tasks에 적용시킬 수 있다.
BERT는 이와 같은 방식이 pre-trained representations, 특히 fine-tuning의 효율을 저하시킨다고 주장한다. 주요 한계점은 언어 모델이 unidirectional하다는 것이며, 이는 구조상 pre-training 과정에서 비효율적이다. 예를 들어 OpenAI의 GPT의 경우 left-to-right 구조를 사용하는데, 모든 토큰은 현재 위치보다 항상 좌측에 위치한 토큰만을 참고할 수 있다. 이러한 한계는 sentence-level tasks에서 sub-optimal이고, token-level tasks에 fine-tuning을 적용할 때도 부정적 요인으로 작용할 수 있다.
따라서 BERT는 이러한 한계점을 개선시키기 위해 "Masked Language Model"과 "nexst sentence prediction"이라는 pre-training 메소드를 제시한다(Cloze task에서 영감을 받았다고 한다).
BERT
Model Architecture
BERT 모델은 기본 Transformer(Attention is All You Need)과 유사한 구조를 가지고 있으며 논문은 GPT와 비교하기 위한 BERT-BASE(L=12, H=768, A=12, Total Parameters=110M)와 더 큰 모델인 BERT-LARGE(L=24, H=1024, A=16, Total Parameters=340M) 두 가지 모델 사이즈를 제시했다.
Token Embedding으로 "WordPiece embeddings"를 사용하며 Input Segment는 실제 문장 혹은 연속된 단어의 조합이 될 수도 있다. BERT는 문장 간의 관계를 파악하는 것을 아주 강조하는데, [SEP]와 Segment Embeddings를 통해 sentence separation을 인식한다. 항상 첫번째 토큰으로 입력되는 [CLS] 토큰은 output에서 classification tasks에 대한 추론값을 계산한다.
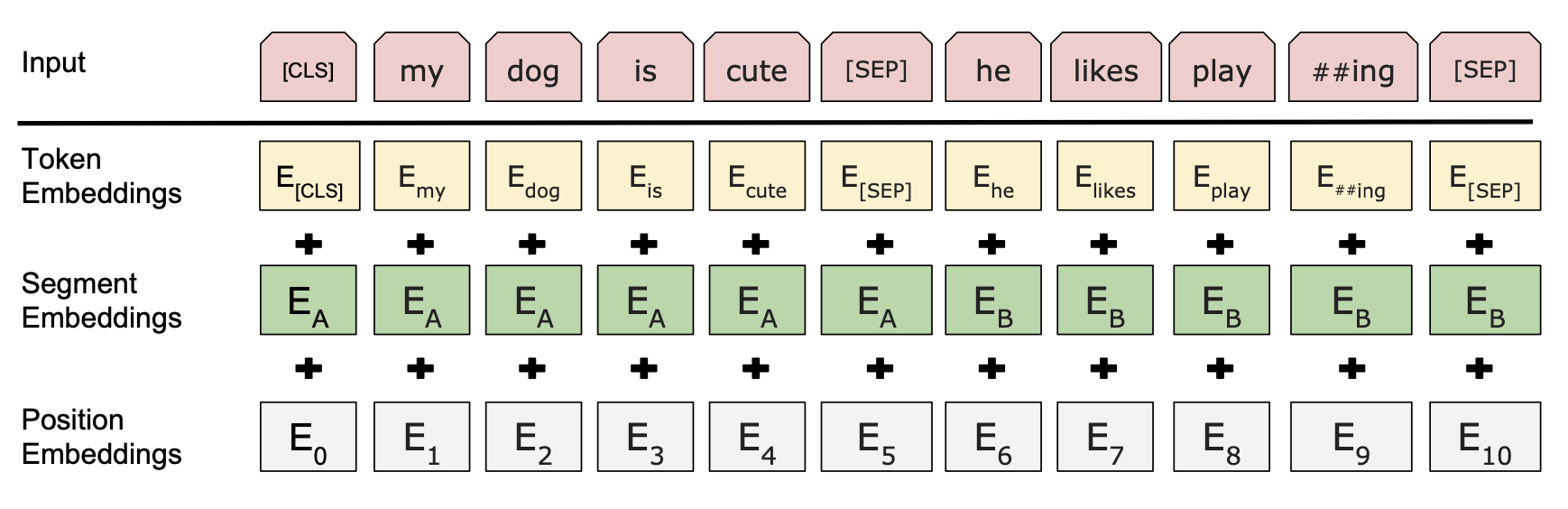
Input representation은 Token Embeddings(WordPiece Embeddings), Segment Embeddings, 그리고 Position Embedding의 합이다.
Pre-training
BERT의 pre-train은 Masked LM, NSP 두가지의 method를 제시한다.
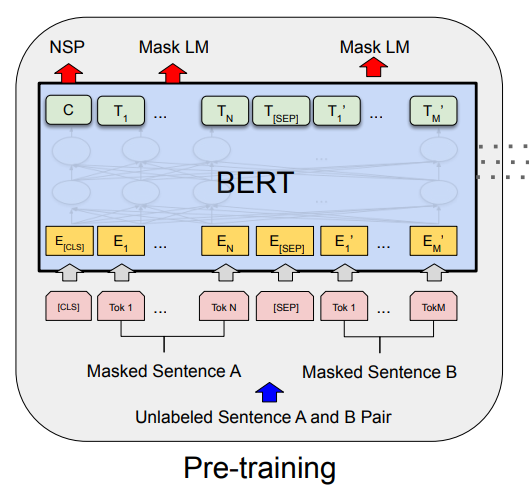
Maked LM은 BERT가 양방향성 pre-training을 진행할 수 있게 한다. Bidirectional representation을 학습시키기 위해선 위의 그림처럼 Input의 일정 부분을 마스킹하고, 모델은 [MASK] 토큰을 예측하는 훈련을 진행하면 된다. Training data 생성자는 모든 입력 시퀀스의 15%의 토큰을 고르고 다음 과정을 처리한다:
1) 골라진 토큰 중 80%는 [MASK] 토큰으로 대체
- ex) I am a student. -> I am a [MASK].
2) 10%의 확률로 random token으로 교체
- ex) I am a student. -> I am a cow.
3) 10%의 토큰은 바뀌지 않음
- ex) I am a student. -> I am a student.
Next Sentence Prediction(NSP)는 문장 간의 관계를 이해하는데 도움을 준다. Training example 문장 A와 문장 B를 고를 때, 50%의 경우 B가 원래 A 다음으로 오는 문장이고, 나머지 50%는 무작위로 추출된 문장이다. 위에 그림에서 볼 수 있듯이 토큰 [CLS]가 output을 통해 NSP를 판별한다. 이 학습 방법이 QA와 NLI와 같은 downstream tasks에 적용할 경우 아주 좋은 결과를 보이게 된다.
Fine-tuning
Fine-tuning 과정은 아주 빠르고 간단하다. Pre-trained BERT에서 input과 output을 downstream tasks에 맞는 차원으로 바꾼 후 그대로 학습시키면 된다. Pre-training과 달리 fine-tuning 작업은 단일 클라우드 TPU 에서 1시간이면 충분할 정도로 적은 자원을 필요로 한다.
논문의 Experiment 파트에선 GLUE, SQuAD v1.1, SQuAD v2.0 등에서 SOTA를 달성함을 보여준다.
Ablation Studies
Ablation Studies 파트에선 pre-training tasks의 효과, 모델 size에 대한 효과, 그리고 BERT의 Feature-based에 대한 실험 내용이 기술되었다.
Effect of Pre-training Tasks
BERT의 NSP와 MLM의 효과를 실험한다. BERT-base 모델과 동일한 파라미터를 가진 모델을 NSP task를 제거한 버전과 LTR(left-to-right) & no NSP 버전으로 학습시켜 실험시킨 결과는 다음 표와 같다.
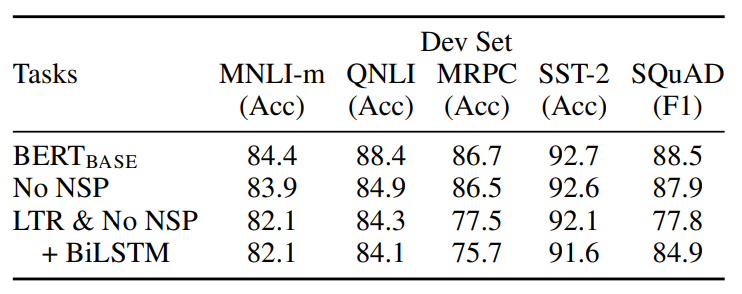
논문에서 주장한 것과 같이 NSP와 MLM이 제거된 모델이 모든 면에서 가장 안좋은 결과를 보였으며, BiLSTM을 추가한 모델은 더욱 좋지 않은 성능을 보인다.
Effect of Model Size
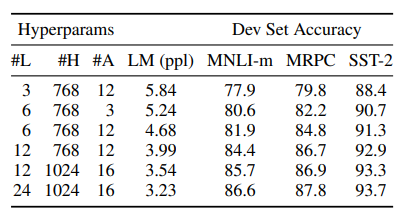
위 그림은 모델 size에 따른 성능 실험표이다. L = 레이어의 수, H = hidden size, A = attention head의 수를 나타낸다. 모델의 사이즈가 클수록 fine-tuned 성능과 pre-training 모두 결과가 더 우수한 것을 확인할 수 있다.
Feature-based Approach with BERT
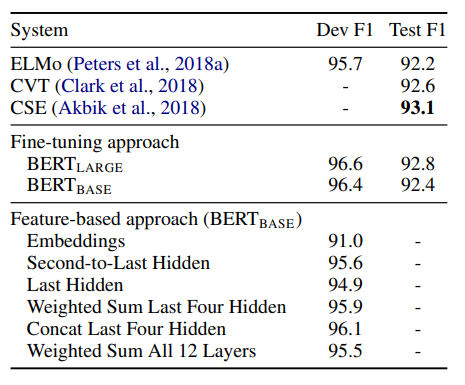
역시나 BERT-large 모델과 BERT-base 모델이 더 나은 성능을 보이는 것을 확인할 수 있다.
Discussions
모델에게 pre-training을 통해 언어에 대한 이해능력을 부여해서 실제 downstream tasks에서 적은 supervised-data로도 좋은 성능을 낼 수 있다는 것이 흥미롭다. AI 모델은 labeled data로 학습을 진행해야 된다는 생각을 가지고 있었는데, 그런 편견을 깨주는 개념인 것 같다. 논문에 GPT와 비교하는 내용이 있어 다음 paper reading은 GPT로 해보려고 한다.
